
Today’s blog post will give an insight into one of the many things that improved with Icinga DB: how host and service history is written to the database, both by the old IDO feature, as well as what has changed with Icinga DB and how this leads to more reliable results.
IDO
To understand the improvement, we first have to understand how things worked before Icinga DB. In the IDO, every time some event happens that is relevant for the history, a database query for writing the event is generated and added to an internal queue within the Icinga 2 process that’s then send to either MySQL or PostgreSQL. These databases tend to be slower (at least compared to Redis, but we will come back to this later), so especially if there are bursts of events like many downtimes starting at the same time, some queries might accumulate in the queue. If at that point, Icinga 2 is restarted or maybe even the whole host system crashes, these queries will be lost, resulting in missing history events.
Now you might be wondering what happens in an HA setup where there is a second Icinga 2 node that should take over in such a situation. On a high-level overview, high-availability (HA) in the IDO works like this: you have two Icinga 2 nodes communicating events to each other to stay in sync. Both of them are connected to the IDO database, but only one is actively writing to the database (the one on the left in the picture below) with the other one being in a standby role (indicated by the dashed line to the database).
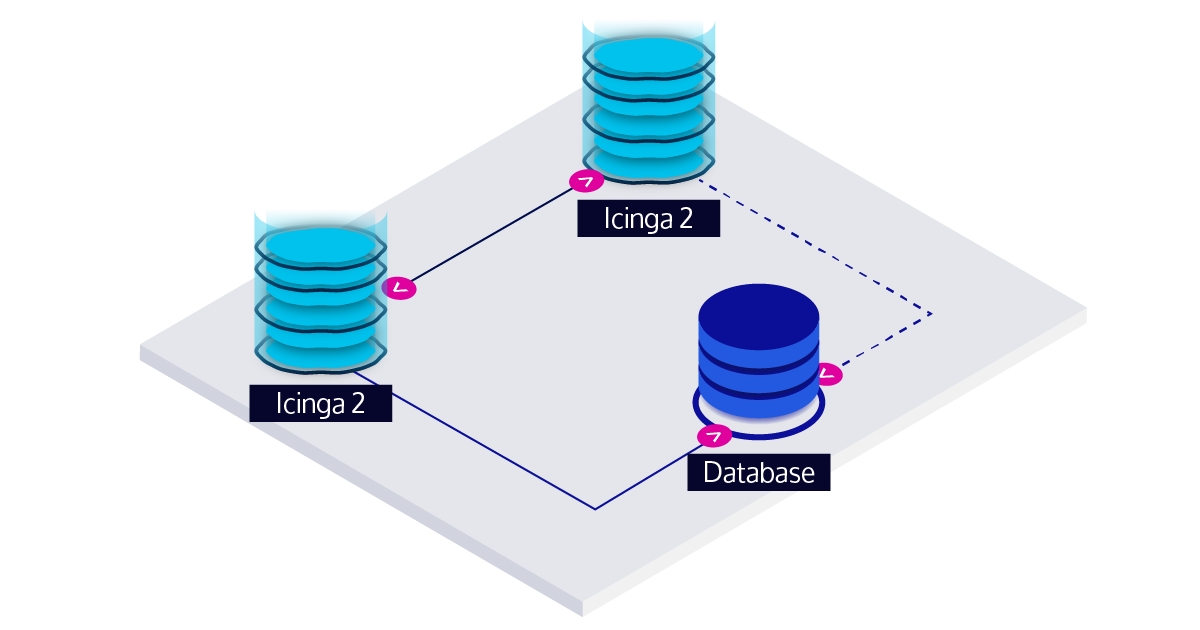
When the standby node detects a failure of the node that was previously active on the IDO database, it will take over. However, this does take a moment and there is no communication between the two nodes on which history events were already written to the database, so each time this happens, you might end up with a small gap in the history data.
Icinga DB
Now, let’s have a look at how things have changed with Icinga DB. One of the key concepts of Icinga DB is that it introduces Redis into the Icinga stack. By being an in-memory database, writing to it is very fast, making it possible to move the history events out of the Icinga 2 process quickly, so that they won’t get lost on Icinga 2 restart (as long as Redis is running). Note that after just being written to Redis, events aren’t persisted to disk yet, so if the whole system would crash, some of them might still be lost.
However, there is another improvement with Icinga DB: the HA feature now works differently so that you end up with an uninterrupted stream of history events written to the database as long as the other instance is still working. For an HA setup with Icinga DB, you not only have a second Icinga 2 instance, but also separate Redis and Icinga DB instances. Again, both Icinga 2 instances communicate the events happening in your monitoring environment with each other. In contrast to the IDO, the Icinga DB feature is always in an active role on both Icinga 2 instances, so both generate a full history stream and write it to Redis. From there, both Icinga DB processes pick up the history stream and write it to the database.
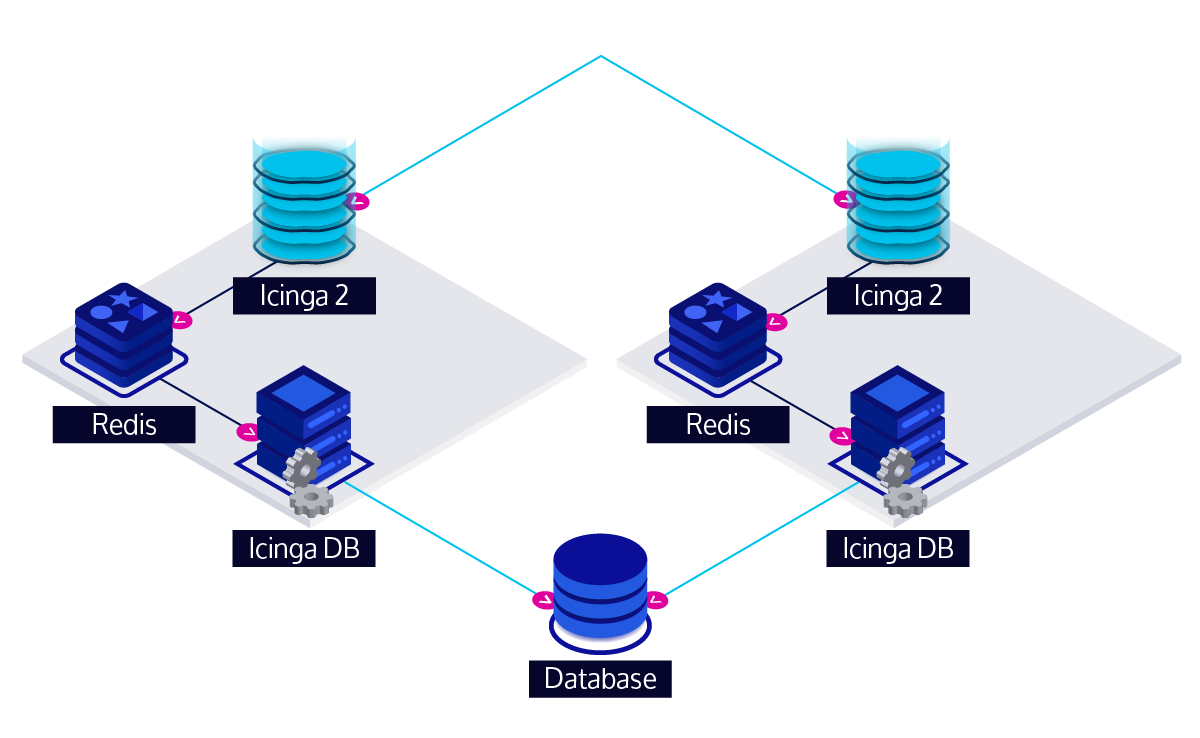
But with two instances writing the full history to the database, why aren’t there duplicate events in the database afterwards? If we had implemented the same with the IDO, this would have happened most likely, but two changes allow us to do better: First, we have taken care that both instances generate absolutely identical events. In order to achieve this, we had to synchronize some additional data between the Icinga 2 instances, for example some timestamps were missing and the active IDO node would just use its local time. Second, by using a hash of the contents of the event as the primary key in the new database schema instead of some synthetic ID, this allows us to detect if the same event was already written by the other instance and avoid writing a duplicate.
This is just one of the many improvements that come with Icinga DB, so if you aren’t using it already, you should give it a try!



